
Capital Meets Carbon: Top 5 Ways Investors Unlock Value Through Sustainability
Highlights from Measurabl and FTSE Russell’s NYC panel on how data-backed strategies are shaping the next era of real estate investing. We were honored to

Safeguarding ENERGY STAR Data: Steps to Take Today, and a Path for Tomorrow
Sign up for a free Measurabl account to protect your data, ensure continuity, and unlock new value—no matter what happens with ENERGY STAR Portfolio Manager.

Measurabl’s Vision for the Future Beyond ENERGY STAR
The questions raised by the potential end of ENERGY STAR are worth asking no matter what comes next By Matt Ellis, CEO and Co-Founder, Measurabl
Introducing Measurabl Intelligence: A Data-Driven View of Sustainability Progress
Measurabl, the world’s leading sustainability data platform for real estate, appoints Kumar Brahnmath as Chief Product & Technology Officer to accelerate global innovation, AI-powered solutions, and sustainability impact.

ENERGY STAR Backup Plan: Best Practices and Checklist
MAY 8, 2025 ENERGY STAR Update: Proposed Elimination from the Federal Budget As a follow-up to our March Communication (seen below) regarding the future of

How PGGM Uses ESGx Securities to Drive Smarter Real Estate Investments
With $220 billion of assets under management (AUM), PGGM is a global leader in responsible investing, allocating 12%—$26.4 billion—to real estate across public and private

Global Student Accommodation (GSA) Expands Relationship with Measurabl to Accelerate Sustainability Initiatives in Europe
GSA leverages Measurabl’s next-generation platform to streamline sustainability reporting, decarbonization, and data automation across its global student housing portfolio London, UK – April 2, 2025

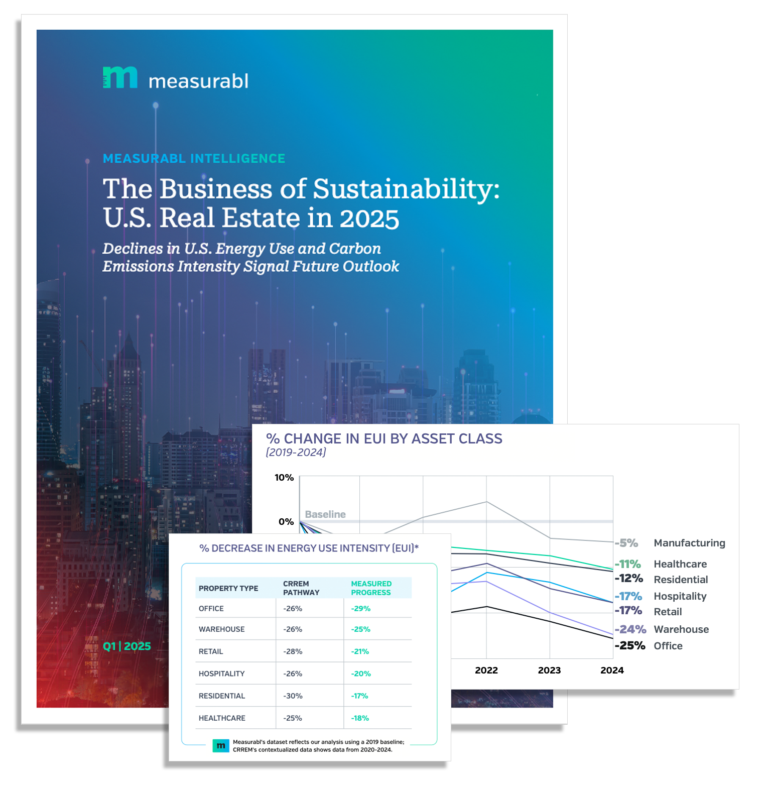
Measurabl’s New Data-Backed Intelligence Report Shows U.S. Real Estate Making Progress on Decarbonization—and Seeing Business Results
Findings show measured declines in energy use intensity across seven property types, cumulative reductions since 2019 across seven property types range from 5% to 25%.
ENERGY STAR FAQ
FREQUENTLY ASKED QUESTIONS What is ESPM? ENERGY STAR Portfolio Manager (ESPM) is a software application for commercial real estate, administered by the U.S. EPA. Real

Measurabl API: Getting Started Guide
This guide provides an overview of the Measurabl API, how to get started, and key information you need to successfully integrate with our platform. What

What’s New at Measurabl: Recent Product Updates & Innovations
Staying ahead in sustainability and compliance means having the right tools to track, report, and act on your data with confidence. The latest updates, part

Measurabl 2024 Updates: Here’s How 2024 Measured Up
As we kick off 2025, we’re reflecting on the incredible strides Measurabl has made last year, thanks to our growing community of customers, partners, board

Measurabl’s Product Innovations for January 2025
This blog is part of a recurring series where we explore Measurabl’s continuous product innovations. Each post will highlight key advancements, milestones, and what’s next

Preparing for GRESB Reporting in 2025: Tips from the Measurabl Team
As a GRESB Founding Partner, Measurabl has led data excellence for over a decade, helping organizations achieve measurable sustainability outcomes. In this blog, we share expert strategies for consistent GRESB reporting success.

Measurabl and BXP Partnership: Reimagining the Built World through Data and Sustainability
As we dive into 2025, it’s worth reflecting on the standout moments from 2024 that continue to shape the future of real estate. One such moment was the CREtech 2024 conference, where industry leaders from Boston Properties (BXP) shared how they are reimagining the built environment by integrating sustainability and technology.
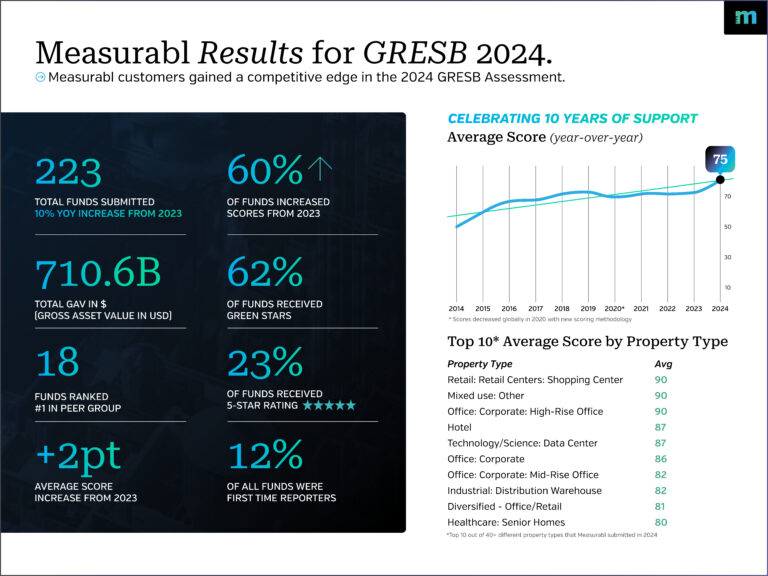
GRESB Scorecard 2024 Insights: Measurabl Customers Lead in Sustainability Excellence
As a Founding Partner of the GRESB Data Quality Working Group, Measurabl has been at the forefront of data excellence for over a decade. As

The Measurabl Mindset: Redefining Sustainable Real Estate
The real estate industry is at a turning point. To thrive amidst evolving standards and shifting market dynamics, today’s leaders need more than strategy—they need a new way of thinking. We call it The Measurabl Mindset.

The Measurabl Minute
Discover how we’re redefining sustainable real estate with groundbreaking partnerships, innovative product updates, and actionable data insights. This month, explore our collaboration with FTSE Russell, new Navigate features, and the release of the ESGx Benchmarks Report. Plus, don’t miss the first episode of the Measurabl Mindset video series and details on upcoming events.